


No Country for Young Engineers 3
AI Edition

Background
In part one, we critically examined the commonly cited benefits of mixed seniority engineering teams and debunked these claims.
In part two, we looked at the diverging career trajectories of engineers and saw that the addition of junior engineers to a team will, more often than not, be detrimental, draining resources and productivity rather than providing the anticipated infusion of vitality and innovation. We also touched on the general characteristics of LLM.
Here in part three, we’ll look at the impact of AI on software engineering and on the career trajectories of engineers at different levels of ability and growth.
Then, in part four, we’ll close with recommendations for hiring and assembling robust engineering teams.
Impact of AI on Engineers

In this section, we’ll walk through the impact of AI on engineers in particular and I’ll provide examples of my own queries trying to demonstrate the facet.
Improved Outcomes with Domain Knowledge
In general, outcomes from LLMs improve markedly when users possess a detailed understanding of the expected results and can elucidate the steps involved in transforming their input into the desired output.
While familiarity with LLMs can be helpful, the primary drivers of output quality are high-quality input and robust domain knowledge as the input mechanism is natural language or code.
This is particularly relevant to engineers as LLMs tend to be quite good at interpreting and generating code on the basis of their training data and small, well-defined syntax it provides.
Example
Specific, domain knowledge: With pure CSS I have two elements. The first one has a max-height: 75% but it may be shorter. The second currently just has a height of 25%. Ideally if the first element was below the max, I'd like the second element to be larger e.g. if the first element was taking up only 25% of the height the second element should be 75%. How can I do this with CSS?
Shutting Down Unproductive Explorations
This is a corollary to having strong domain knowledge. The more you know about what you’re looking for with an LLM and what a correct output looks like the more quickly you can shut down unproductive explorations.
Quickly identifying when you are venturing outside the LLM's knowledge bounds, realizing when the LLM is leading you astray, promptly shutting down unproductive explorations, and understanding the jagged frontier of the LLM’s knowledge boundary can greatly enhance your return on investment when working with LLMs and prevent wasting time and resources.
This is of particular relevance to engineers as many more complex problems can be solved in multiple ways and conversely there is sometimes a right tool for the job. Much like with people, you can fail with LLMs by being overly specific or too vague.
Examples
Overly specific: I’m having an issue with an Angular component not rendering a set of list options in the correct order. The issue was completely unrelated to Angular but was a JavaScript language feature I didn’t understand. In this case I could have wasted an infinite amount of time on the problem because I had seeded the LLM query with bad, extraneous data “Angular” which sent the LLM off looking in the entirely wrong solution space.
Too vague: This SQL query [query] is failing what’s wrong with the syntax? In the case, nothing was wrong with the query it was completely correct but the particular application I was using and the subset of language support it implemented wouldn’t work with the provided query. Note, this is generally an easier problem to solve, if you have additional knowledge, than the previous since I can use follow up queries to refine my request albeit at the cost of wading through some irrelevant responses.
Learning Boost in Unfamiliar Domains
All engineers receive a significant learning boost in unfamiliar domains from large language models (LLMs), experienced engineers receive a larger boost.
LLMs excel as educational tools, particularly effective for those with limited prior knowledge of the field, but where the field is well-defined, and has a substantial corpus of literature. For example: American history, the C# language, data science in Python, or OAuth workflows. Provide the user knows enough to ask for the right thing to learn about and there is a robust data set on the topic LLMs are a great teaching tool as natural language (asking questions) is a great way to learn about a topic thanks to the individualized learning and rapid responses it provides.
Experienced and proactive learners benefit disproportionately, as they find novel concepts increasingly accessible and the time to learn a new topic reduced. They can also leverage their existing foundational knowledge to ask more specific and accurate initial and follow up questions to improve the output they receive back.
This does not mean LLMs are ideal for learning all new domains. When working with topics where the corpus is small, obscure, or those where there is a recency bias it is often better to go directly to the documentation or consider contemporaneous resources on the basis of both recency and specificity.
Diminished Value for Single-Domain Specialists
LLMs diminish the value of single-domain specialists due to their effectiveness at style transfer, e.g. Excel experts or COBOL programmers.
Style transfer in LLMs refers to the process of altering the style of a given text while preserving its original content. The popular examples of this are often things like “rewrite this news report as a Shakespearean sonnet” or “rewrite this essay in Pirate style”.
This ends up being incredibly useful to engineers because it means if you can conceptualize what you want to do as code (or natural language) or reference an existing implementation (you know how something similar works), you can rapidly reach proficiency with a new language or paradigm by leveraging your existing knowledge in a very direct, task-directed manner.
This ability again directly relates to the ability of the user to express precisely what they want which directly ties to general knowledge and experience.
Examples
I have the following PostgreSQL query can you rewrite it in C# with EntityFramework?
I’ve written the following function in TypeScript please convert it to Python keeping the type structure intact
I’ve attached an image of some mathematical equations from a research paper please convert them into Python code.
Rote Task Automation
LLMs excel at rote task automation.
We’ve already discussed LLMs particular effectiveness when working with a large corpus or performing a style transfer operation.
A lot of routine engineering work includes tasks that can leverage this such as generating boilerplate code, documentation, or type strings, or executing mundane transformations such as string replacements, formatting, and file renaming.
This is certainly beneficial to all engineers but due to their clear requirements and conceptual ease these tasks often end up accruing to more junior engineers meaning more of their tasks are likely good tasks for LLMs to do most of the heavy lifting.
Value from Review and Iteration Experience
Experienced professionals, skilled in reviewing and guiding iterative improvements with their human colleagues, can derive significant value from applying these skills to LLMs and AI tools. Their expertise in refining processes and outputs translates into more effective use of AI technologies.
LLMs are useful tools but a lot of the time invested in them as we’ve discussed involves iterating on both inputs and outputs. If you have a lot of experience submitting requirements, revising requirements based on feedback, reviewing solutions, and iterating on those solutions you will have a good skill set in place for working with LLMs. For instance, if you have experience writing and reviewing design docs and pull request reviews those skills highly transferable to working with an LLM both in generating prompts and reviewing the LLM’s the responses for accuracy and relevance.
Summary
Across the board, AI tools notably enhance the proficiency and output of senior engineers compared to their junior counterparts. Seniors are adept at integrating their extensive skill sets and experience with AI capabilities, effectively distinguishing useful insights from misleading ones. The skills they have honed in directing, managing, and reviewing the work of their human colleagues translate well to orchestrating AI interactions, allowing them to maximize productivity and navigate the limitations and inaccuracies inherent in AI outputs.
Conversely, while AI can accelerate the learning process for junior developers in unfamiliar domains, they face a significant challenge due to the scarcity of hands-on tasks that foster skill development. In many cases, they are competing directly with the LLM on the content, speed, and quality of what they are delivering. The seemingly magical capabilities of AI might also inhibit their growth in critical areas. As others have noted with writing, replacing learning with LLM generation allows achieving a baseline proficiency quickly but without the growth that comes from developing the skill yourself.
Furthermore, without substantial domain knowledge and experience in iterative review, juniors are less equipped to avoid inefficiencies and identify errors in AI outputs, potentially leading to prolonged and unproductive engagements with the technology.
Outcomes
Let’s examine the landscape of developer outcomes in a post-AI world using the developer categories we previously developed.

The Plateau for Productivity Has Been Raised
The most interesting adjustment we need to make is that because each individual engineer can now do more the plateau of what constitutes a productive engineer has gone up.
In absolute terms, all engineers can now do more, the more productive engineers can do much more, and most importantly, this effect does not scale linearly, the top 1% engineer gets more added value than the top 10% engineers, etc.
A previously, marginally profitable engineer is now unprofitable in a pool of engineers. Unlike a baseball team where you must field the same number of players companies can now field smaller teams of more productive engineers.
There are a couple other interesting implications here. The first is that companies are updating their expectations of what a developer can produce based on the introduction of AI. This does seem to be occurring in the marketplace at large based on developer salaries and hiring (although, as always there is a confluence of factors at work). This shift as with previous flows in engineering hiring behavior seems to be driven by the movements of big tech and followed by everyone else.
But an interesting corollary is that companies that do not update their expectations for developer output based on AI tools and may still be measuring their output next to the legacy plateau may actually see a perceived bump in outcome from previously unprofitable developers. This may lead to a bifurcated market of high skill AI-aided developers at the high end of the market and low-skill AI-aided developers at the bottom end of the market.
Another implication here, because the plateau of productivity has been raised, new developers take absolutely longer to get across the gap to profitability with the raised plateau. Borrowing again from the Gartner Hype Cycle, the trough of disillusionment is wider for engineers and their employers. This provides a two-fold hindrance to new engineers, it takes their employers longer to get to a positive expected value from the engineer, albeit with the benefit absolutely more productive when you get there. And there are more opportunities for the engineer drop dead in the desert of disillusionment before reaching the plateau.
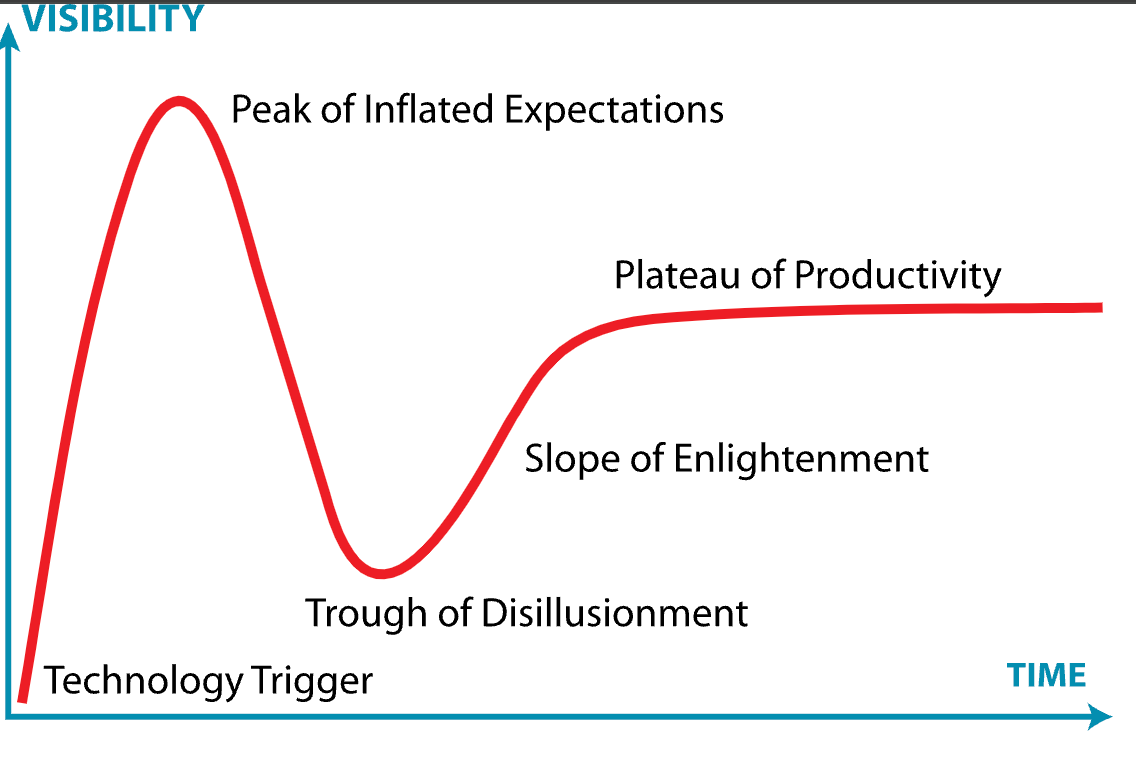
The Support Structure Has Been Cleared
The previous model of engineering development was similar to the development of young saplings before they could grow to giant tree-shaped developers, juniors were nurtured in a protective ecosystem of well-defined, delegated tasks, exercises in familiarization, and carefully scoped work that provide them fertile soil to set down roots and start to rise up.
AI tools have razed this undergrowth of “grunt work”. LLMs thrive specifically on the type of tasks that were previously given to junior developers: well-defined and scoped work, boilerplate code generation, bugs with clear reproduction and finite scope, repetitive tasks, and proposing technology alternatives, generating throw-away proof of concepts, summarizing learnings, and rewriting documentation.
LLMs have also greatly simplified, streamlined, and quickened the process a senior engineer would go through with a more junior engineer. Previously, the senior engineer would write up a task for a junior engineer, often doing much of the initial thought and design in ticket so the younger engineer could focus on the implementation. The junior engineer would take this “prompt” and write code to satisfy the “prompt”. They would then put this code up for review, it could often use improvement. The senior engineer would provide feedback and commentary as necessary, suggesting potential code revisions, and this loop would continue until the junior’s code was acceptable. With AI this loop is nearly instantaneous. Give the AI the “prompt” directly and ask it to generate the code. The result will again likely be sub-par, you then provide the AI feedback and have it iterate on the code, or determine it’s close enough and take the AI output and revise it yourself.
An asynchronous multi-threaded process has become a faster, synchronous, single-threaded process. The simple act of writing the requirements directly to an LLM and iterating on it provides a less labor-intensive, faster feedback loop that provides faster, higher-quality results.
Conclusion
Previous generations of engineers faced a series of Mario-esque steps that could be conquered through gradual improvement, rising above the plateau of productivity.


New engineers, in the world of LLMs, start out a New Game on level one facing a giant gap that can only be crossed with advanced jumping techniques, power-ups, and precision timing, but lack the benefit of having gained those powers and experience from earlier levels.

Senior developers start in New Game+. They can utilize the domain knowledge and experience reviewing and iterating on human code to utilize the new LLM power up on top of their existing skills and tools to reach new heights.
Without any explicit gatekeeping a moat has been created that makes it harder to provide value as a junior engineer while entrenching the more productive senior engineer.
What else could happen?
There’s no shortage of ways I could be wrong.
Life is short, craft long, opportunity fleeting, experimentations perilous, judgment difficult.
Hippocrates
A couple spring to mind:
Pipeline Changes: The previous college to big tech pipeline may simply become a more familiar college to introductory company (those still using outdated plateau of productivity), to big tech allowing a different model for young engineers to develop the skills necessary to be absolutely productive in a controlled environment.
Improvements in LLMs: Either through improvements in usage, agentic workflows, “chain-of-thought”, “ensemble modeling”, or “consensus” models, reduction in costs, or some as yet undetermined method the existing benchmark of LLM performance is substantially changed so as to alter the dynamic proposed here.
Loss of Surplus Engineers: I don’t think software engineers will disappear, short of true AGI, it’s too valuable a field and demand remains. However, salaries are returning to earth, and junior developer salaries faster. So for the utility-minded, but not particularly software-passionate young person considering a career in engineering, other careers, e.g., doctor, dentist, lawyer, etc., may start to look more attractive again. This winnowing at the top of the funnel may lead to a healthier cohort, more turtle hatchlings that can make the perilous journey to adulthood.
Pedagogy improves: Either via AI or changes in curricula engineers enter the field on average much closer to, or above the plateau of productivity in which case. the calculus for junior engineers changes again and makes them fruitful additions to a team.
Homo Habilis: My gut is that the benefit of LLMs comes from the skill of the user in the domain rather than skill in the use of the tool e.g. “prompt engineering”. But this may change in the future such that being an “AI native” conveys the same advantages as being a “digital native” once did.
Next Up
To end on a more positive note, the final part of this series will discuss recommendations for effective hiring in this evolving landscape.
Stay tuned!
Believe I am too pessimistic (or optimistic) in my assessment of engineering outcomes in light of AI? Do you have a different value metric that you believe I overlooked? Did I miss or misjudge some impact of AI on engineers? Is there a future I did not sufficiently consider? Your feedback is valued and appreciated!
The Mario analogy makes your case.